The model:
The model uses operators that model the responses of cells in MT. They
are tuned to the direction of motion within their receptive fields and have
an excitatory and inhibitory region. These operators essentially subtract
the motion from adjacent regions of the visual field.
Image of operators:
Each region of the visual field is processed by a group of these
operators that differ in their preferred direction of motion and the angle
of the axis between the excitatory and inhibitory regions.
Image of model:

The maximally responding operator at each location projects to the next
layer of cells. These cells are tuned to a radial pattern of input, in terms
of the preferred directions of motion, from the motion subtraction
operators. The maximally responding cell in this layer will have a center of
the radial pattern that coincides with the translation direction of motion
of the observer.
Image of model:
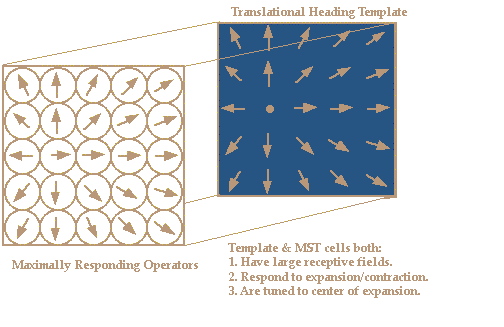
The model works by removing rotational components of image velocity,
leaving only the image velocity due to observer translation. The preferred
directions of the maximally responding motion-subtraction operator across
the visual field form a radial pattern.
Image of flow field for translation and rotation through 3D cloud:

Image of preferred directions of operator responses:

The model computes heading well in the presence of rotations.
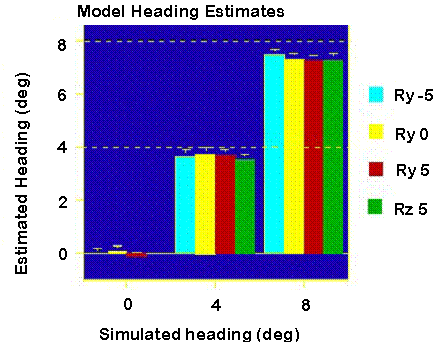
In addition, the magnitude of the
motion-subtraction operator's response is proportional to the change in
depth between the excitatory and inhibitory regions. Thus, we can detect
the location and magnitude of depth changes in the scene:
Image of operator response magnitudes
for wall in front of plane.
Added observer rotations do not
affect this response:
Image of operator responses in the
presence of rotations:

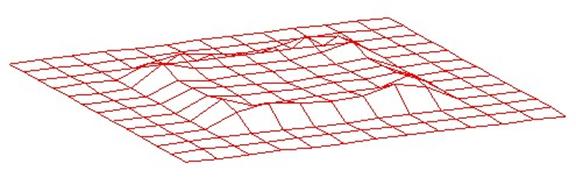
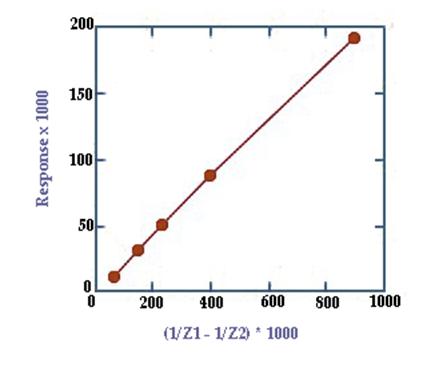
The responses at a depth edge are
proportional to the difference in inverse depth between the two surfaces.
Image of graph
of responses:
The work is supported by NSF grants #IBN-0196068, and #IBN-0343825.




