An Environment for Interpreter-based Projects for the
Programming Languages Course
Introduction
The programming languages course is a fundamental part of the undergraduate curriculum in computer science. [ACM91][CRA99] Students are encouraged to consider how elements of programming languages complement each other and can be used to create powerful abstractions. At the same time, students learn how language elements constrain programming styles. Thus, students are encouraged to see programming languages as objects of study, and not merely as the syntax for expressing an algorithm.
The programming languages course presents a pedagogical challenge because it has a number of competing goals. One goal is to broaden the students' experience with a variety of programming language features. This approach is on firm philosophical foundations, following Aristotle [Ari52] and Locke [Loc52] both of whom argued that specific experience is required in order to recognize general principles. Another goal is to cultivate an understanding of how language features are implemented, since every language construct raises implementation concerns. The challenge is how best to teach a diversity of languages and features in a unified way while fulfilling implementation considerations.
Many programming languages courses compare and contrast the semantic and syntactic features of a number of distinct programming languages and discuss some parsing theory. This comparative or traditional approach enriches the students' experience of language diversity and can be used to illustrate common concepts that underlie many programming languages [DeJi95, Pra84, Seb99, Set90]. The student gains practice and insight into different programming language paradigms by studying "real" programming languages. (i.e. Design issues are discussed, abstractions are explored, and programming is practiced and students are exposed to a variety of concepts, abstractions, and paradigms and get first-hand experience with real languages.) However the relationship between implementation and language features is often not satisfactorily explained and the complexities of real languages make mastering individual concepts difficult. For example, consider teaching the concept of class using Smalltalk. Students often confuse the concept of class with Smalltalk's presentation of classes in a browser environment; if they have not been exposed to C++ they think that object-oriented classes means having a browser.
Deeper confusions arise with semantic issues. Differentiating which features of imperative languages are due to static scoping and which stem from strong typing, for example, is confusing to students. Semantic confusion is often exacerbated because programming language design and implementation courses emphasize language support for abstraction and how this abstraction influences programming style. Because language abstractions result from many design choices, students can easily confuse abstractions with designs. For example, objects (an abstraction) can be created in functional languages through first class procedures. However, students often miss the design tradeoff between first-class procedures versus a simpler procedure call mechanism because of the focus on the abstractions that can be created with the feature (i.e. objects).
Another issue often addressed in a programming languages course is understanding the costs, both in efficiency and complexity, involved in different language features. We can lecture on cost, but design decisions are often so intertwined that changing a single feature to demonstrate the corresponding change in cost is not possible. As a result, students often lack the means to fully appreciate costs of design decisions. Finally, without some experience in implementation details, students do not fully grasp the implementation impact of design decisions.
An alternative is an interpreter-based approach [Kam90] [Fri92]. In this approach, programming language features are presented with the aid of an interpreter which implements the features of interest. This approach exposes implementation concerns in a natural way. Additionally, the interpreter acts as a direct and unambiguous explanation of the run-time semantics of language features. By modifying and extending the interpreter, students gain concrete experience with a language concept. Examining interpreters for several languages also exposes the common principles shared between languages. The difficulty is how to avoid emphasizing minutiae specific to a particular interpreter at the expense of larger issues. As interpreters for most actual programming languages are too complicated for use in the classroom, another challenge is to find a suitable language interpreter and access to the source code for modifications and extensions.
We advocate a hybrid approach which combines the comparative and interpreter-based approaches. [BaKi94] [BaKi95] [BaKi95f] [Bru99] The goal is to expose students to all the concepts central to a traditional programming language course but also give experience with the implementation of various languages. Towards this end, the lecture material is largely based on the traditional programming course emphasizing exposure to a variety of languages, language similarities and differences, and some parsing theory. This material is supplemented by interpreter-based projects. This approach differs from a pure interpreter-based approaches (e.g. [Kam90]) in two ways: the interpreter projects are ancillary teaching tools, rather than the main focus of the course; and secondly, since central language concepts are presented in traditional lectures, the interpreter projects can be highly simplified but still illustrative. The projects give student experience relating language syntax and semantics with an implementation, but avoid the danger of bogging students down in a large interpreter implementation.
In addition to interpreter projects, students are also provided with simple demonstration languages which can be used to teach by counter-example. This method involves keeping all aspects of the simple languages constant while one particular feature is changed to explore the effect of that design on the expressive power and efficiency of the language. Therefore the use of simple demonstration languages enables teaching by counter-example to be effective not only by isolating the studied feature, but also because experimenting with an actual language reinforces concepts in an active way, as opposed to passive memorization. In this setting, a system for building and experimenting with interpreters is desirable. We are developing and propose redesigning and enhancing MuLE, a software environment, which supports this teaching goal.
Progress to Date
The MuLE system supports the development of interpreter-based projects for multiple language paradigms. MuLE stands for MUltiple Language Environment. It is written in Scheme and is designed to facilitate the creation of interpreter-based programming languages projects. For each paradigm, MuLE provides a simple but limited interpreter. As part of their class work, students can experiment with, extend or modify the appropriate interpreter. The MuLE system contains four simple languages (Simple Object Oriented Programming Language {SOOP}, SImple Functional Language {SiFL}, Simple PrOCedural Language {SPoc}, and Simple LogIC Language {SLic}) from different paradigms that students can simultaneously program in.
A single environment for the projects and the interpreters for each paradigm share a common architecture and are stylized to facilitate easy comprehension. Furthermore, MuLE has a common interface for each supported language paradigm.
MuLE Architecture
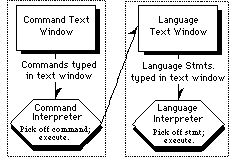
MuLE presents the student with a text window in which commands can be typed. A command interpreter parses the typed text and implements the appropriate action using a fetch/parse/execute cycle. From this command window, the student can give commands to access programming paradigms supported by MuLE, as illustrated in Figure 1.
Figure 1: MuLE structure.
In Figure 1, the rectangles represent windows that appear on the screen and the hexagons describe the treatment of text typed in the associated window. Accessing a programming paradigm supported by MuLE causes a new text window to appear on the screen. Text entered in a language paradigm window is parsed by a paradigm-specific interpreter which implements the semantics. An actual screen shot from MuLE appears in Figure 2.
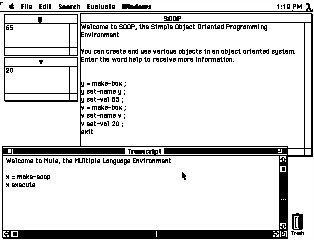
Figure 2: MuLE screen shot.
Commands entered in the bottom "Transcript" window are interpreted by the MuLE command interpreter. In this example, the user has entered MuLE commands to open the OOP window (top right) and to start the OOP interpreter running. Commands in the OOP window are interpreted by the OOP interpreter as statements in the Simple Object-Oriented Programming Language (SOOP). In this example, the user has entered SOOP statements to create two box objects, name the objects y and v respectively, and to set the value of y to be 65 and to set the value of v to be 20. Box objects display themselves as windows, in this case as the two windows in the upper left of Figure 2.
The bottom MuLE command window of Figure 2 corresponds to the left-hand side of Figure 1. The OOP window at the upper right of Figure 2 corresponds to the right-hand side of Figure 1.
The source code for both the MuLE central command interpreter and the SOOP interpreter is accessible to the student and can be modified as part of a class project.
The MuLE implementation contains the central command interpreter and a paradigm-specific interpreter for each supported language paradigm. Since a lot of interpreter code should be reused, MuLE also contains a library of building-block routines for the creation of interpreters. Additionally, MuLE offers an object-oriented library of building-block routines for manipulating text windows. Object orientation was achieved by using Scheme's support for first-class procedures to represent objects as functions.
The MuLE system should be extensible. To add a new paradigm or interpreter-based environment to MuLE, the existing libraries can be used to create an object encapsulating a "skeleton" interpreter for the new paradigm and for manipulating a text window interface to the interpreter. The interpreter library routines should be used to complete an interpreter for the new paradigm. Finally, the command interpreter can be edited to implement a command to access the new paradigm object.
Integrating MuLE into a Programming Language Course
MuLE is not intended as the primary means of presenting programming language information; it is too stylized and simplistic. Rather, MuLE is intended as an tool used to reinforce the standard presentation. We envision a programming language course in which students compare a variety of programming paradigms, augmented with project assignments using MuLE. In this context, the projects reinforce the issues raised in lecture and give students experience relating syntax and semantics with an implementation. Additionally, we can use the MuLE implementation itself to illustrate a lecture point while simultaneously preparing students for a project assignment.
MuLE projects generally consist of either adding support for a new language paradigm or extending an existing paradigm with new language features. For many students, actually working with a language feature's implementation is a deep learning experience. The student moves from an abstract understanding to mastery.
Counter examples also demonstrate why modern languages have made similar decisions. A simple language is first presented with a design feature, students experiment with the language to discover the advantages and liabilities presented by the feature and, finally, the feature is replaced by a different feature and the process is repeated. By exploring a less desirable feature first and a more popular feature second, students learn why the second feature is preferred. MuLE projects are/can be an effective medium for demonstration by counter-example.
Counter-example Example
As an example of teaching by counter-example, consider the design choice between dynamic and static scoping strategies. Dynamic scoping is not widely used at present. Lisp, SNOBOL and APL are languages traditionally associated with dynamic scope whereas a number of popular programming languages use static scope (e.g. Pascal, C, Ada). When teaching by counter-example, the aim is to experiment with a language which uses dynamic scope, and then experiment with the same language implemented with static scope. This experimentation is difficult to conduct using the real languages like Lisp or Pascal, and certainly implementation issues are glossed over.
With MuLE we can teach the difference between static and dynamic scope using SiFL, a simple functional language that is part of the MuLE system. SiFL normally uses dynamic scoping, but it is easily reconfigured to use static scoping. Thus it is straightforward to demonstrate the effects of both scoping mechanisms to students. Students can experiment with SiFL programs which are interpreted by either dynamic or static scope implementations of SiFL. Furthermore, students can see how scope choice influenced implementation by examining the two SiFL implementations.
For example, consider the following SiFL program:
(assign y 10)
(assign p1 (proc (x) (* x y)))
(assign p2 (proc (y) (p1 y)))
(p1 3)
(p2 3)
The first statement defines a global variable named y with value 10. The next statement defines the function p1 which uses a variable named y but does not define it. Next the function p2 is defined which contains a local definition of a variable named y, and which calls p1. The final two statements are function calls to p1 and p2 respectively, with the value 3 as the parameter.
The function call to p1 returns the value 30 regardless of whether dynamic or static scoping rules are used. In either case, the reference to y in the body of p1 refers to the global variable named y with value 10. In contrast, the value returned by p2 depends on the scoping mechanism used because the scope rules change the value returned by the nested call to p1. If static scoping is used, then the reference to a variable named y in p1 refers to the global variable named y with value 10, and p1 returns the value 30. If dynamic scoping is used, then the variable named y in p1 refers to the local variable named y with value 3 (defined in p2), and p1 returns the value 9.
Although this presentation alone is useful in the classroom, the presentation would be reinforced if the students have access to SiFL. Using SiFL, student's can test their hypotheses about the differences between static and dynamic scope rules interactively and design experiments to test their understanding. Furthermore, the scoping rule is easily changed in the SiFL interpreter which facilitates comparison between the static and dynamic scoping implementations of SiFL. Understanding the implementation further reinforces the concepts.
Current variable bindings in SiFL are maintained in a list called an environment. When an expression is evaluated, the parsed expression and this environment are passed to a function, named
execute, which evaluates the parsed expression in the context of the environment. Every variable that is assigned a value at the global level is stored in the environment as a name-value pair. When a procedure is called a local environment is created as a list of name-value pairs within the global environment. When other functions are called (or a function is called recursively) new lists representing local environments are added to the environment. When a procedure finishes execution, its local environment is removed.For every SiFL statement that is parsed successfully, the interpreter stores relevant information in a record. For a function, this record is called a
proc and it contains three fields, the formal arguments, the parsed function body and a lexical level. The appropriate lexical level for a function is determined during the parsing.The scope rule determines how the environment is searched when a variable reference appears in an expression. Under dynamic scoping rules, the environment is searched so that the most recent definition of a variable is found. Under static scope rules, the lexical level is used like a static chain pointer to control the search. In the SiFL's implementation, a single function implements the search code, and only a few lines of the search code are concerned with using the lexical-level/static chain pointer. Consequently, it is relatively easy to disable these lines to change SiFL from static scoping to dynamic scoping.
Thus it is possible to demonstrate to students the essential concept of scoping, the environment in which a procedure is evaluated, at both a high level and an implementation level. The implementation of SiFL is enough that the changes necessary to create different scoping can be easily identified and explained. There is an immediate connection between the concept, the resulting language feature, and the implementation. No "real-life" language implementation, such as Pascal, C, or Scheme, can be conveniently used to demonstrate all three of these areas.
Plan of Work
Software Improvements
We have an incomplete implementation of MuLE whose shortcomings we propose to address in this project. Although past work has generated interest in MuLE, implementation shortcomings pose technical barriers to widespread adoption of MuLE. Removing these barriers will demonstrate whether MuLE stands on its own merits as an effective part of a programming languages course.
First, MuLE is implemented in a commercial version of Scheme (EdScheme) which costs between $80 and $150 per license, limits the usability of MuLE's graphical user interface, and runs only on the Macintosh (the necessary graphical interfaces are missing in the PC/Windows version of EdScheme). We propose to redesign MuLE in DrScheme, a free (GNU Public License) version of Scheme which runs on Windows (95/98, NT), UNIX, and Macintosh, and which has strong graphical support for GUI development. Second, we propose to employ good software engineering principles and software quality assurance practices to develop a robust MuLE implementation. For example, we want automated unit tests for each component of MuLE to ensure each component meets its specification so that system quality assurance can be performed quickly after changes. We would also like to investigate the use of code-coverage tools that would measure the completeness of our unit tests. Likewise, we want automated testing, to the extent possible, of the integrated system as well. Finally, MuLE offers simple demonstration languages which can be used to teach by counter-example. We propose to develop a number of counter-example modules similar to those in the following table:
| Counter-example | Example |
|---|---|
| Dynamic Scoping | Static Scoping |
| Pass-by-name | Pass-by-Value, Reference, Value-Result |
| Right Associativity | Left Associativity |
| No Precedence | Normal Arithmetic Precedence |
| Full Evaluation | Short Circuit Evaluation |
| Polymorphism | Operator Overloading |
| Dynamic Typing | Static Typing |
| No typing Global Environment only | Local Environments |
Table 1. Language feature examples and counter-examples | |
Table 1 consists of a two-column listing of features. The first column delineates the "counter-example" and the second column states the more common "example" implementation. We propose to pre-package a number of counter-example modules as part of the standard MuLE distribution.
Dissemination
The developed MuLE software package (complete source, assignments, examples etc.) will be made freely available and distributed via the internet using common mechanisms like the Web and ftp sites. As in the past, results of this project will be presented at conferences devoted to teaching [BaKi94] [BaKi95] [BaKi95f]. In addition, we are currently negotiating with Addison-Wesley to write a programming languages textbook around the MuLE software. The publisher has sent our proposal out to reviewers and has thus far received favorable feedback. (See attached letter from Frank Ruggirello, Publisher of Computer Science, Econ, and Finance for Addison Wesley Longman.) We feel it is essential to get the software done first and right, before we can embark on using it as a centerpiece for the proposed text. The marketing for the textbook, should the software be fully developed, would ensure wide dissemination. Although the textbook is another avenue of dissemination, we want to emphasize that the complete MuLE software package proposed here will remain freely available without the textbook.
Experience and Capability of the Principal Investigators
Both investigators on this proposed project already have demonstrated a long term commitment to the project's success, with a publication record of work in this area since 1994, and have demonstrated willingness to disseminate results with the academic community [BaKi94] [BaKi95] [BaKi95f]. The investigators are motivated by a love of a teaching and the desire to improve the quality of education offered to students. This work is grounded in their experience teaching programming language courses and the feedback from students.
Evaluation
A comprehensive evaluation would undoubtedly take years of carefully controlled experiments which is beyond the scope of this proposal. It is important to take advantage of assessment and evaluation at many different points. To this end, the publisher we are negotiating with has already conducted reviews of this proposal. This early review/assessment of this project shows we are committed to "checking our work as we go" so to speak.
Early evaluation aside, it is important to gather some meaningful, evaluative data on the success of the project. Both assumative and formative evaluations will be useful in evaluating the MuLE software project. Assumative evaluation addresses whether or not MuLE is actually a useful tool in the classroom. There are two dimensions to this assumative evaluation. The first dimension questions whether MuLE actually increases learning. Do students comprehend and recall concepts better? The second dimension questions whether MuLE aids teaching. Does MuLE aid in the presentation of material? On the other hand, formative testing focuses on software usability issues, such as its ease of use and its overall design.
Assumative Evaluation
Establishing a measure of how well students learned course material is difficult since differences in teaching style, text, student preparedness, basic student abilities and other factors will impact the results. We cannot completely account for all of these differences, but we will attempt to determine the students' starting point with a pre-test and then use a post-test to measure learning accomplished. Topics for both the pre-test and post-test would include but are not limited to the following.
Basic programming abilities, knowledge of language theory (grammars, parse trees, etc.), knowledge of parsing, understanding of basic design and implementation principles of different types, constructs and paradigms (functional, imperative, object-oriented, logic), knowledge of interpreters and translators.
These assumative pre/post-tests will be given both to students who participate in a course using MuLE and in a control course not using MuLE. Two "cooperating faculty" members who will be teaching the Programming Languages course from Ithaca College and Sacred Heart University have agreed to participate. (See attached commitment letters from Dr. F. Grodzinsky, Sacred Heart University and Dr. W. Dann, Ithaca College.) Final results will be determined in the spring of '01 (see MuLE Project Timeline and Evaluation Timeline) as work on the textbook begins.
To answer the second set of questions about whether MuLE made teaching itself better, we will ask the faculty member new to MuLE to evaluate their experience in the classroom. This evaluation will concentrate on the pedagogical features of MuLE. Sample questions include the following.
How has MuLE changed your course?
How hard was it to integrate MuLE into the course?
How much classroom time was needed to explain MuLE? Was this too much time?
Did you perceive that MuLE increased student comprehension of how to program in different paradigms?
Did you perceive that MuLE increased student comprehension of programming language theory (e.g., parsing, grammars, etc.)?
Did you perceive that MuLE increased student comprehension of programming language implementations?
Did you perceive that students liked MuLE and the MuLE assignments?
What changes in MuLE would make it easier to use? More effective pedagogically?
Did you have a lab assistant in the course? How easily did s/he learn MuLE? Could you/Would you use MuLE if you did not have a lab assistant? Why not?
Formative Evaluation
We also propose to use a formative evaluation to determine if our work improving/redesigning the software has been successful. In this evaluation we will ask questions like: Is MuLE easy to use? Do students like the software? Is the software sufficiently robust for its purpose? To perform this evaluation, we will design feedback forms that will allow evaluators (both the faculty member and the students) to write what they think. All students who use MuLE in the classroom will fill out feedback forms. Secondly, we will record our own experiences using MuLE in our classrooms, but of course we are concerned that our own familiarity with the software will bias our opinion. Consequently, it is important that the cooperating faculty new to the software evaluate their experience.
Evaluation Protocol Design
Proper feedback forms are difficult to create. Although we will attempt to cover a broad spectrum of crucial concepts in the assumative tests, the form and phrasing of questions in all the evaluations can skew the results. Also, there are a number of factors other than MuLE, like the motivation and enthusiasm of the professor, that impact student learning but are hard to separate out of evaluation results. Careful design of the feedback format, questions, and testing formats will be necessary for the evaluation data to be useful. For this reason we are seeking a third-party consultant/testing expert more qualified than the authors to help design and administer the evaluation protocol and assess the results, and include this funding in our budget request. (We are proposing allowing approximately 7% of our budget for this purpose.) Naturally, we will take advantage of electronic dissemination and submission of feedback to encourage high return rates by making it as easy as possible.
One of the committed outside cooperating faculty and their corresponding set of students will participate in this round of formative testing.
Evaluation Future
If this early testing shows promise, wider testing and evaluation outside of our own institutions and cooperating institution will be done. We will recruit other sites to participate in a comprehensive beta test of the software. Our goal in this phase of the testing will be to ensure that MuLE is easy to install, use and fits pedagogically into a wide variety of programming languages courses.
To this end, we will carefully recruit a variety of institutions to participate. Our criteria will be designed to ensure that different types of schools (liberal arts, comprehensive universities, research universities, engineering schools, etc.) with different types of programs (BA, BS), that have students with varying backgrounds (experience with interpreters or not, experience with Scheme or not) and with instructors with varying experience can successfully incorporate MuLE into the programming languages course. We will troll for possible test sites by putting a call-for-participation in the ACM SIGCSE Bulletin, and on the SIGCSE members e-mail list (sigcse.members@acm.org). The selected participants will be briefed on MuLE and the testing procedures at a birds-of-a-feather session at the 32nd SIGCSE Technical Symposium, 2001.
We will also submit a MuLE workshop proposal to the 32nd SIGCSE Technical Symposium to provide exposure to the MuLE system and to generate interest and potential beta test sites.
Finally, we will test the software in conjunction with the development of the textbook. At least some of the instructors who review the textbook will be asked to use and comment on the software.
Summary
The Programming Languages course should expose students to a diversity of languages, explore programming language similarities and differences, and discuss language implementation issues. In our experience, interpreter-based projects can be useful in meeting these educational goals, and provide a particularly natural context for considering language implementation concerns.
We believe in a hybrid approach which includes elements of the traditional and interpreter-based approaches to teaching the Programming Language course. Our approach differs from a pure interpreter-based approach (e.g. [Kam90]) because interpreter-based projects and demonstrations are ancillary teaching tools, rather than the central focus.
We will develop a teaching tool for the programming languages course which enhances the students' grasp of fundamental programming language concepts, constructs and paradigms and deepens the students' appreciation of the relationship between language features and their implementation. The tool is a software environment, MuLE, supporting interpreter-based projects for multiple programming language paradigms (e.g. object oriented, imperative/procedural, functional, logic programming).
We have an incomplete implementation of MuLE whose shortcomings we propose to address in this project. These shortcomings are technical barriers to widespread adoption of MuLE. Removing these barriers will demonstrate whether MuLE stands on its own merits as an effective part of a programming languages course.
Evaluation Protocol Timeline
Spring 2000
Tasks:
Begin Evaluation Protocol Design
Develop formative evaluation
Draft assumative evaluation
Distribute formative evaluations
Personnel:
2 PIs,
Evaluation Consultant,
Cooperating Faculty
Summer 2000
Tasks:
Finalize assumative evaluations
Perform initial formative tests
Personnel:
2 PIs,
Evaluation Consultant,
Cooperating Faculty
Spring 2001
Tasks:
Pre/post-assumative tests given
Formative evaluations given
Evaluate testing results
Create beta test program
Personnel:
2 PIs,
Evaluation Consultant,
Cooperating Faculty
MuLE Project Timeline
Spring 2000
Tasks:
Requirements outlined
Architecture refined
Rewrite utility code
Rewrite MuLE
Add GUI code
Rewrite SiFL and SPoc
Sub-unit testing
Personnel:
1 PI, one course reduction
2 students, 10hrs/wk
(programming)
Summer 2000
Tasks:
Rewrite SLic and SOOP
Add new objects with new GUI for SOOP
Create plug-ins for SiFL/SPoc
System integration
Personnel:
1 PI, 4 wks (full-time)
1 PI, 2 wks (full-time)
2 students, 4 wks (full-time)
Fall 2000
Tasks:
Finish plug-ins
Test code
Personnel:
1 PI, one course reduction
(Testing/Evaluation)
2 students, 10 hrs/wk
(Programming)
Spring 2001
Tasks:
Use in PL course
Personnel:
Cooperating Faculty
MuLE Project Timeline Explanation
This schedule is designed to implement MuLE using standard software engineering life-cycle techniques. We plan to begin with requirements definitions, then perform subsystem implementation and testing, integration, and finally system integration, evaluation and verification. The implementation of this plan is as follows:
1. Requirements and specifications definition. Architecture Design.
Currently a working prototype of the MuLE system has been developed and tested. [BaKi94] [BaKi95] [BaKi95f] Based on this testing, we have determined the requirements (services and constraints under which the software must operate) for MuLE. In the spring semester we will begin by using these requirements and the test results to develop specifications for MuLE, the various interpreters, the utility and GUI code, and the plug-in components. The specifications will include user interfaces, functional interfaces, and data dictionaries. Specifications will be written in natural language.
We will also develop a plan for validation and verifying the software. Validation plans will ensure that MuLE meets classroom requirements. In other words, we will test whether the MuLE specifications were correct, i.e., that it performs the pedagogical functions that we need in the classroom. The verification plan will ensure that MuLE meets specifications. This plan will test MuLE to ensure that it operates correctly.
In addition to developing specifications, we will design the final software architecture of MuLE. The architecture has already been established, so the purpose here will be to ensure that the architecture fits the specifications and to make any minor adjustments necessary to enable the plug-ins components to work. The architecture is a function-oriented design in keeping with our decision to implement MuLE in a functional language, Scheme.
Finally, we will make plans for a user manual. The manual will be completed by students as the individual components are completed.
This work will be completed early in the semester.
2. Sub-unit Implementation.
In addition to completing the specifications in the spring of '00, we will also begin unit implementation and testing. In particular, we plan to rewrite the utility code, the GUI code, and the base MuLE system. Most of this implementation will be done by students. In addition, we will implement the SiFL and SPoc interpreters. Most of this work will be done by the PI, with particular components of the interpreters completed by students (depending on their experience).
Draft user manuals will be completed by students as they finish sub-units. The drafts will be examined during the second group meeting.
The sub-unit tests will be completed and the initial integration and testing will begin. The second group meeting in this semester will concentrate on the later.
3. Finish sub-unit implementation, begin integration and testing.
This phase, which will take place in the summer of 2000, will concentrate on the completion of the final interpreters for the MuLE system and the coding of plug-ins for the various interpreters. Depending on the experience of the student workers, they will complete one or more of the interpreters and most of the plug-ins. The PIs will code one or more of the interpreters and will supervise and test the implementation of the plug-ins.
The first meeting in the summer will be used to assess progress, introduce any new students to the project, integrate and test any code that was completed since the last spring meeting, reassess the specifications, and plan and organize the summer work. The principle goal for the summer is to complete coding of all interpreters and integrate them into the MuLE system.
Sub-unit testing of the individual interpreters will be done as they are completed.
4. System Integration.
The second group meeting in the summer of 2000 will be used to integrate all interpreters into the MuLE system. We will perform initial integration testing at this time to ensure that the components work together correctly. Problems will be corrected or logged depending on the time.
We will also examine the drafts of the user manuals at this second meeting. Problems will be identified for students to correct.
5. Validation and Verification.
In the fall of 2000 we will concentrate on any remaining integration issues identified, but not corrected, at the end of the summer. The first group meeting in the fall will identify these issues, develop a plan for correcting them, and assign responsibilities.
The majority of the fall semester will be used to test the MuLE system. The first meeting will also include a review of the testing plan developed during the specification phase. Specific testing responsibilities will be assigned.
Specific design and implementation problems will be tracked by the PIs during this period and students will be given both testing and correction responsibilities.
The second group meeting of this semester will be used to review test results, identify any remaining problems, and to provide the final editing of the user documentation.
References
[ACM91] ACM/IEEE-CS Joint Curriculum Task Force (1991). Computing Curricula 1991. New York, ACM Press.
[Ari52] Aristotle, Posterior Analytics, Book 2, Chapter 19, 100A from Aristotle I, Britannica Great Books, 1952
[BaKi94] Barr, John and L.A. Smith King, "Interpreter-based Projects for a Traditional Programming Languages Course", The Journal of Computing in Small Colleges, Volume 10, Number 2, November 1994.
[BaKi95] Barr, John and L.A. Smith King, "An Environment for Interpreter-based Programming Language Projects", twenty-sixth SIGCSE Technical Symposium on Computer Science Education, Volume 26, Number 1, March 1995.
[BaKi95f] John Barr and L.A. Smith King, "Teaching Programming Languages by Counter-Example", The Proceedings of the Eleventh Annual Eastern Small College Computing Conference, New Rochelle, NY, October 20-21, 1995.
[Bru99] Bruce, Kim, "Formal Semantics and Interpreters in a Principles of Programming Languages Course", Thirtieth SIGCSE Technical Symposium on Computer Science Education, Volume 39, Number 1, March 1999.
[CRA99] http://www.cra.org/Activities/snowbird/slides/Turner/sld007.htm, Computer Sciences Accreditation Board slides (CSAB) accessed 5/21/99
[DeJi95] Dershem, Herbert L. and Michael J. Jipping, Programming Languages: Structures and Models, PWS Publishing Company, 1995.
[FiGr93] Fischer, A., and Frances Grodzinsky, The Anatomy of Programming Languages, Prentice Hall, 1993.
[Fri92] Friedman, D., Wand, M. and Haynes, C., Essentials of Programming Languages, The MIT Press, 1992.
[Kam90] Kamin, Samuel, Programming Languages: An Interpreter-Based Approach, Addison-Wesley Publishing Company, 1990.
[Loc52] Locke, An Essay Concerning Human Understanding, Book 2, Chapter 1, Section 2, Britannica Great Books, 1952
[Pra84] Pratt, Terrence W., Programming Languages Design and Implementation, 2nd Edition, Prentice-Hall, Inc., 1984.
[Seb99] Sebesta, Robert W., Concepts of Programming Languages, 4th Edition, Addison-Wesley, 1999.
[Set90] Sethi, Ravi, Programming Languages Concepts and Constructs, Addison-Wesley Publishing Company, 1990.